

Voice Agent Architectures Explained: Cascading vs Native Multimodal Pipelines
Everyone wants to build “voice agents”, but that term hides two very different architectures.
The first is the classic cascading pipeline: speech-to-text → LLM → text-to-speech, all coordinated by your backend.
The second is the newer native multimodal realtime pipeline, where the client talks almost directly to a realtime model session capable of handling speech input/output in one loop.
I sketched both architectures to understand the tradeoffs more clearly. In this post, I’ll break down how each pipeline works, where latency comes from, what your backend is responsible for, and when I’d choose one over the other.
Why voice agent architecture matters?
Building a voice agent is not just about plugging an LLM into a microphone. The architecture you choose determines:
how fast the assistant feels
whether you can swap STT/TTS vendors independently
how easily you can add tools and business logic
how much conversational nuance the system can preserve
how much your backend stays in the critical path
how hard it is to debug latency spikes or broken turns
At a high level, most production systems today fall into one of two buckets:
Cascading voice pipeline
Separate STT, LLM, and TTS services connected by backend orchestration.Native multimodal realtime pipeline
A realtime model session handles the conversational loop, while the backend acts more like a sidecar for auth, tools, and control.
1) Cascading voice pipeline

In the cascading design, the voice stack is decomposed into three separate stages:
Speech-to-Text (STT / ASR)
Converts user audio into textLLM reasoning/generation
Takes the transcript + context and produces a responseText-to-Speech (TTS)
Converts the response text back into audio
The backend orchestrates all three stages and sits directly in the middle of the conversation loop.
High-level flow
The client (browser / SIP endpoint / phone integration) streams audio to the backend
The backend forwards audio to an STT provider
The STT system emits partial/final transcripts
The backend sends the transcript + conversation context to an LLM
The LLM streams back response text
The backend forwards the generated text to a TTS provider
TTS returns synthesized audio
The backend streams audio back to the client
Breaking down the components
Client
The client can be:
a browser using WebRTC/WebSocket audio streaming
a SIP/telephony system for phone calls
a mobile app streaming microphone audio
Its job is simple: capture audio, send it upstream, and play audio responses back with low latency.
Backend
The backend is the conductor of the entire pipeline.
It is responsible for:
managing websocket sessions
buffering audio chunks
forwarding audio to STT
maintaining conversation state
calling the LLM with the latest transcript + context
invoking TTS for response synthesis
streaming synthesized audio back to the client
enforcing business rules, auth, logging, and analytics
In a cascading pipeline, the backend is not optional infrastructure — it is the core orchestrator.
STT / ASR
The STT layer converts incoming speech into text. Typical providers include:
OpenAI Whisper / realtime transcription offerings
Azure Speech-to-Text
Deepgram
AssemblyAI
ElevenLabs speech recognition offerings where relevant
This stage often also handles:
voice activity detection (VAD) — detecting when the user starts/stops speaking
turn detection — deciding when the user’s utterance is “complete enough” to send to the LLM
partial transcript streaming
LLM
Once the backend has a usable transcript, it calls the LLM. This is where:
intent understanding happens
tool decisions happen
conversation memory is used
response text is generated
For voice systems, teams often prefer small, fast models for the conversational path because latency matters more than perfect reasoning depth for every turn.
TTS
Finally, response text is synthesized into speech using providers like:
ElevenLabs
Deepgram
AssemblyAI / others depending on the stack
The backend then streams the generated audio to the client.
Why teams still use cascading pipelines
Advantages
Modular and replaceable
You can swap Deepgram for Whisper, or ElevenLabs for another TTS provider, without redesigning the whole system.Maximum backend control
The backend sees the transcript, the prompt, the tool calls, and the generated response. That’s valuable for compliance, debugging, analytics, and guardrails.Tool orchestration is straightforward
Since the LLM call already goes through your backend, executing tools, calling APIs, or injecting business logic is easy to control.Best when speech is only one part of a larger workflow
For example: contact-center agents, internal enterprise assistants, booking flows, or customer support systems with strict backend workflows.
Drawbacks
Higher latency because STT, LLM, and TTS are separate hops
Speech expressiveness can be lost when everything is collapsed into text between stages
Interruption handling is harder because the system has to coordinate stop-speaking / start-speaking behavior across multiple services
More moving parts means more operational complexity
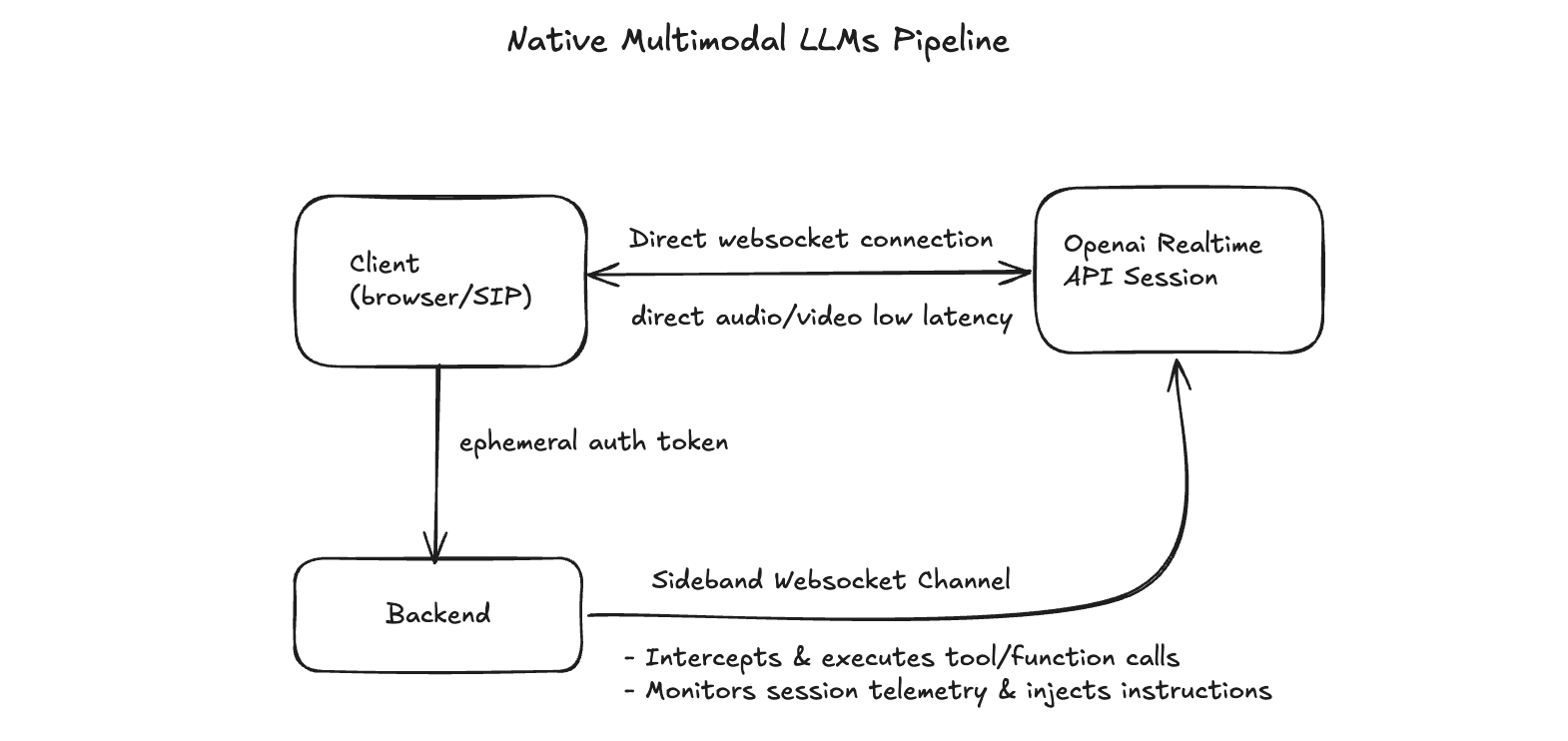
2) Native multimodal realtime pipeline

The second architecture is structurally different.
Instead of routing every conversational turn through separate STT → LLM → TTS services, the client establishes a direct low-latency connection to a realtime multimodal model session.
The backend still exists, but it no longer sits in the middle of every audio token flowing through the system. Instead, it acts more like a control plane / sideband service.
High-level flow
The client requests an ephemeral auth token from the backend
The client uses that token to establish a direct websocket/realtime connection to the model provider
Audio/video streams directly between the client and the realtime session
The backend maintains a sideband channel to the session for:
tool/function execution
telemetry monitoring
session updates / injected instructions
business logic hooks
This changes the role of the backend significantly.
Breaking down the components
Client
In the native multimodal setup, the client becomes much more important.
It is responsible for:
establishing the realtime connection
sending live audio (and sometimes video)
receiving streamed speech responses directly from the model session
handling interruptions and playback state on the client side
Because the client is closer to the model, the interaction can feel more conversational and immediate.
Backend
The backend does not disappear. It just moves out of the direct audio path.
Its responsibilities now shift toward:
minting ephemeral session/auth tokens
maintaining a sideband websocket / control channel
intercepting and executing tool calls
injecting dynamic instructions or policy updates
collecting telemetry, usage, and observability data
enforcing app-specific business rules
This is a crucial mindset shift:
In a cascading pipeline, the backend is the conversation orchestrator.
In a realtime multimodal pipeline, the backend is often the session controller and tool executor.
Realtime multimodal model session
The model session now handles much more of the conversational loop natively:
streaming speech input
turn-taking behavior
response generation
speech output
sometimes multimodal context like audio + text + image/video
Instead of manually chaining STT + LLM + TTS, you’re delegating that conversational stack to the model provider.
Why the native multimodal pipeline feels faster
The biggest architectural win is that the system removes multiple explicit stages from the critical path.
Instead of:
client → backend → STT → backend → LLM → backend → TTS → backend → client
you get something closer to:
client ↔ realtime model session
with the backend participating only when needed.
That reduces:
extra network hops
orchestration overhead
cross-service coordination delays
It also enables more natural interaction patterns like:
faster interruptions / barge-in
lower response latency
smoother turn-taking
tighter speech-to-speech conversational flow
When I’d choose each architecture
I’d choose a cascading pipeline when…
I need full control over the stack
I want to independently choose the best STT, LLM, and TTS vendors
tool execution and business workflows are central to the product
I’m building for enterprise / contact-center / workflow-heavy use cases
I need strong logging, auditability, and stage-by-stage debugging
I’d choose a native multimodal realtime pipeline when…
the core product value is real-time conversation quality
low latency is the top priority
I want more natural interruptions and turn-taking
I’m building a voice assistant, AI tutor, interviewer, sales caller, or realtime support agent
I’m comfortable delegating more of the speech loop to the model provider
If I had to summarize the tradeoff in one line:
Cascading pipeline = control and composability (flexibility, low cost)
Native multimodal pipeline = speed and conversational fluidity (less flexible, high cost, low latency than cascading pipeline)



